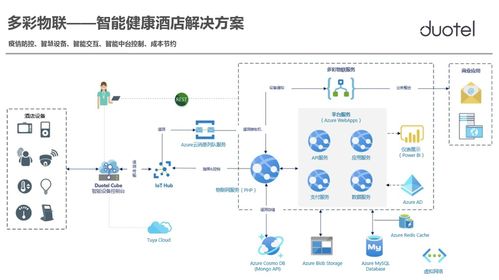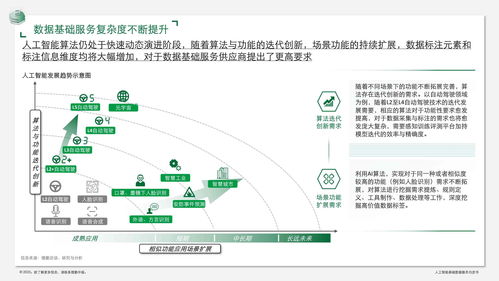
在人工智能技术飞速发展的浪潮中,基础数据服务与基础软件开发构成了驱动行业前行的两大核心支柱。本白皮书旨在系统阐述两者在AI生态中的关键作用、内在联系及发展趋势,为行业参与者提供战略参考。
一、 人工智能基础数据服务:智能的基石
人工智能,尤其是监督学习和深度学习,其性能高度依赖于训练数据的规模、质量与多样性。基础数据服务正是为模型“喂养”高质量“数据燃料”的产业环节。它涵盖了从数据采集、清洗、标注到管理的全生命周期服务。
- 数据采集与汇聚:通过多渠道获取原始数据,包括公开数据集、网络爬虫、传感器以及特定场景下的定制化采集,构建原始数据池。
- 数据清洗与预处理:对原始数据进行去重、纠错、格式标准化、脱敏等处理,消除噪音,提升数据可用性。
- 数据标注与增强:这是核心价值环节。通过人工或半自动化方式,为图像、文本、语音、视频等数据添加机器可理解的标签(如物体框、语义分割、情感分类)。数据增强技术则通过对现有数据进行变换(如旋转、裁剪、添加噪声),有效扩充数据集,提升模型的泛化能力。
- 数据管理与治理:建立高效的数据存储、检索、版本管理和安全合规体系,确保数据资产的可控、可信与可持续利用。
高质量的基础数据服务直接决定了AI模型的上限,是算法创新和模型迭代不可或缺的前提。
二、 人工智能基础软件开发:能力的引擎
如果说数据是“燃料”,那么基础软件就是构建和驱动AI模型的“引擎”。它提供了从底层计算到上层应用开发的全栈工具与框架。
- 计算框架与库:以TensorFlow、PyTorch、PaddlePaddle等为代表的深度学习框架,提供了构建、训练和部署神经网络的底层基础设施和高级API,极大地降低了AI研发门槛。
- 开发平台与工具链:包括模型开发IDE(如Jupyter Notebook)、自动化机器学习(AutoML)平台、模型压缩与优化工具、可视化调试工具等,旨在提升开发效率与模型性能。
- 部署与推理引擎:将训练好的模型高效、稳定地部署到云端、边缘设备或终端,涉及模型转换、服务化封装、性能优化和资源调度等技术,如TensorRT、OpenVINO等。
- 系统级软件:包括针对AI计算优化的操作系统、驱动程序、集群调度系统(如Kubernetes)等,为大规模分布式训练和推理提供稳定的系统环境。
基础软件的成熟度,直接关系到AI技术从实验室原型到规模化产业应用的转化效率与成本。
三、 协同共生:数据服务与软件开发的深度融合
数据服务与软件开发并非孤立存在,而是呈现出深度协同与融合的趋势:
- 软件赋能数据服务:基础软件为数据服务提供自动化、智能化的工具。例如,利用主动学习、预标注模型等技术,可以大幅提升数据标注的效率和一致性;数据管理平台则依赖于强大的数据库和中间件软件。
- 数据驱动软件优化:真实、海量的业务数据反馈是优化基础软件(如编译器、调度器)性能的关键依据。软件需要不断适配更复杂的数据类型和处理需求。
- 一体化平台兴起:市场上涌现出集数据标注、模型训练、部署管理于一体的MLOps平台或AI开发平台,将数据流水线与软件开发生命周期无缝衔接,实现数据、模型、代码的统一管理与迭代。
四、 未来展望与挑战
面向两大基础领域将面临以下关键趋势与挑战:
- 数据层面:向多模态、3D数据、稀缺场景数据拓展;对数据安全、隐私保护(如联邦学习、差分隐私)的要求日益严苛;追求更高程度的自动化、智能化标注。
- 软件层面:追求极致的性能与效率,支持更大规模参数模型的训练与推理;推动软硬件协同设计(如AI芯片专用指令集与软件栈);降低使用复杂度,向“开箱即用”的平民化方向发展。
- 协同层面:标准与接口的统一将促进数据与工具链的更流畅交互;对可解释AI、AI治理的需求将推动产生新的基础软件工具和数据规范。
结论
人工智能基础数据服务与基础软件开发,是支撑AI产业大厦的“地基”与“梁柱”。唯有夯实数据根基,铸就软件利器,并促进二者深度融合、迭代演进,才能充分释放人工智能的潜力,赋能千行百业的智能化转型。产业各方需加大在这两个基础领域的投入与合作,共同构建健康、繁荣、可持续的人工智能生态体系。