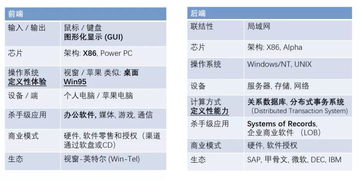
随着人工智能技术的飞速发展,语音识别与语音合成已成为现代软件开发中不可或缺的一部分。通过Python这一强大的编程语言,开发者可以轻松地构建出能够“说话”和“听懂”的智能软件。本文将带你走进Python人工智能开发的世界,探索如何制作一个功能丰富的有声软件,并了解其背后的语音识别系统。
一、语音识别系统的基础知识
语音识别(Automatic Speech Recognition, ASR)是将人类语音转换为文本的技术。它通常涉及以下几个步骤:
- 音频采集:通过麦克风等设备捕捉声音信号。
- 预处理:包括降噪、分帧等操作,以优化音频质量。
- 特征提取:常用梅尔频率倒谱系数(MFCC)等技术提取语音特征。
- 模型识别:使用深度学习模型(如循环神经网络RNN、Transformer)将特征映射为文本。
Python中常用的语音识别库包括SpeechRecognition和Vosk,它们支持多种语音识别引擎,如Google Speech API和CMU Sphinx,让开发者能够快速集成语音识别功能。
二、打造有声软件:语音合成技术
语音合成(Text-to-Speech, TTS)是将文本转换为自然语音的过程。通过Python,你可以实现多种声音风格的合成,包括:
- 萝莉音:清脆、可爱的声音,适合游戏或娱乐应用。
- 御姐音:成熟、优雅的声音,常用于导航或客服系统。
- 大叔音:低沉、稳重的声音,适合播报或教育软件。
- 正太音:稚嫩、活泼的声音,可用于儿童应用或动画配音。
Python的pyttsx3和gTTS库提供了简单的语音合成接口。例如,使用pyttsx3,你可以轻松设置语音速率、音量和声音类型:`python
import pyttsx3
engine = pyttsx3.init()
engine.setProperty('rate', 150) # 设置语速
engine.setProperty('volume', 0.9) # 设置音量
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[1].id) # 选择声音类型(如女性声音)
engine.say("你好,欢迎使用有声软件!")
engine.runAndWait()`
对于更高级的声音定制,可以考虑使用深度学习框架如Tacotron或WaveNet,它们能生成更自然、多变的语音。
三、整合语音识别与合成:制作智能有声软件
结合语音识别和合成技术,你可以创建一个交互式的有声软件。例如,一个简单的语音助手可以这样实现:
- 语音输入:使用
SpeechRecognition库捕获用户语音并转换为文本。 - 文本处理:分析用户指令,如“播放音乐”或“讲个笑话”。
- 语音输出:根据处理结果,用
pyttsx3合成相应的语音回应。
以下是一个基础示例:`python
import speech_recognition as sr
import pyttsx3
初始化语音合成
engine = pyttsx3.init()
语音识别
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("请说话...")
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio, language='zh-CN')
print(f"识别结果:{text}")
# 根据文本生成语音回应
engine.say(f"你说的是:{text}")
engine.runAndWait()
except sr.UnknownValueError:
engine.say("抱歉,我没有听清楚。")
engine.runAndWait()`
四、人工智能基础软件开发要点
在开发过程中,需注意以下几点:
- 数据准备:高质量的语音数据集对模型训练至关重要。
- 模型选择:根据应用场景选择合适的深度学习模型,如使用
TensorFlow或PyTorch进行定制开发。 - 性能优化:考虑实时性和准确性,优化算法和硬件资源。
- 用户体验:设计直观的界面,确保语音交互流畅自然。
五、应用场景与未来发展
有声软件和语音识别系统已广泛应用于智能家居、车载系统、教育工具和娱乐应用中。随着人工智能技术的进步,未来的语音系统将更加智能化和个性化,例如通过情感识别调整语音风格,或实现多语言实时翻译。
Python为人工智能开发提供了强大的工具链,无论是语音识别还是合成,都能让开发者轻松实现“让软件说话”的梦想。无论你想听萝莉音、御姐音还是其他声音,都可以通过代码自由选择。现在,就开始动手,打造属于你自己的有声软件吧!